
Estimation de Fermi
Article Wikipedia : https://fr.wikipedia.org/wiki/Estimation_de_Fermi
En physique et d'autres sciences, une estimation de Fermi ou problème de Fermi, encore appelée question de Fermi ou exercice de Fermi, est un problème d'estimation conçu pour enseigner la manière de faire des approximations correctes, sans données précises mais à partir d'hypothèses judicieusement choisies.
Journaux liées à cette note :
Anthropic sous-vend-il ses abonnements ou surtaxe-t-il son API ?
Comme je l'ai mentionné dans cette note, les abonnements Claude sont beaucoup plus économiques que l'offre par API :
- L'offre Pro à $20 est 8 fois moins chère que l'offre API (pay as you go) : $163
- L'offre Max 5x à $100 est 13,5 fois moins chère que l'offre API (pay as you go) : $1354
- L'offre Max 20x à $200 est 13,5 fois moins chère que l'offre API (pay as you go) : $2708
Un ami me demande à ce sujet :
Est-ce qu'ils sous-vendent leur abonnement (Claude Pro, Max…) ou est-ce qu'ils arnaquent en pay as you go (via l'API) ?
Je n'ai fait aucune recherche à ce sujet, mais voici les explications qui me viennent à l'esprit.
Toute organisation opérant un service numérique gourmand en ressources — qu'il s'agisse de puissance de calcul ou de stockage — doit trouver un équilibre pour rentabiliser une infrastructure coûteuse sur un usage moyen, tout en absorbant des pics de charge qu'il serait trop onéreux de provisionner en permanence, même lorsqu'ils sont prévisibles.
Par exemple, Twitter dans ses premières années (2007-2012) était célèbre pour sa page "Fail Whale" — une baleine affichée aux utilisateurs en lieu et place du service quand les serveurs saturaient. Les événements mondiaux en temps réel (élections, Coupe du monde) suffisaient à faire tomber la plateforme. Je n'ai aucune information interne de Twitter de cette époque, mais clairement, Twitter n'avait pas trouvé de bonne stratégie pour garantir une qualité de service qui puisse suivre sa croissance.
Une stratégie classique sur Internet pour maîtriser cette croissance est l'ouverture par invitation, comme Gmail en 2004 et Dropbox en 2008. Elle permet à l'organisation de contrôler le rythme d'adoption en distribuant des invitations au fur et à mesure qu'elle déploie de nouveaux serveurs.
L'inférence des services d'agent conversationnel est surtout consommatrice de computation — les GPU — et tous les utilisateurs souhaitent utiliser à fond leur limite de tokens, surtout avec les AI code assistant. Anthropic souhaite lisser l'usage de leurs GPU dans le temps, dans le mois. C'est pour cela qu'elle définit des quotas sur 5h et par semaine. Ces quotas leur permettent de lisser et de contrôler davantage l'usage de leur infrastructure.
Estimation de Fermi du coût d'un abonnement Claude Max 5x
Je me suis lancé dans une estimation de Fermi pour estimer le coût brut d'un abonnement Claude Max 5x.
Mon estimation s'appuie sur le modèle Qwen3-235B-A22B comme point de comparaison, faute de données publiques sur l'architecture interne de Claude Sonnet. Précision méthodologique importante : les benchmarks officiels de Qwen (SGLang) mesurent (tokens_input + tokens_output) / temps — c'est donc un throughput mixte, pas uniquement de la génération.
En croisant ces benchmarks avec les résultats de GPUStack sur H100, et avec l'aide de Sonnet 4.6, j'estime qu'un serveur Scaleway "H100-SXM-8-80G — 128 vCPUs — 8 GPUs — 960 GB" loué à 16 810 € / mois peut traiter environ 20 à 40 milliards de tokens d'entrée par mois selon la longueur moyenne des prompts, soit approximativement 30 000 millions de tokens.
Si j'estime qu'un abonnement Claude Max 5x permet de traiter environ 400 millions de tokens d'entrée par mois pour Sonnet, un seul serveur H100-SXM-8-80G peut alors servir :
30 000 M tokens / 400 M tokens = 75 utilisateurs
Si je pars du principe que Scaleway marge à 20% le prix du serveur, cela donne un coût infrastructure par utilisateur de :
16 810 € × 0,8 / 75 = ~179 € par utilisateur par mois
Ce qui fait presque le double du prix d'un abonnement Max 5x.
Je suppose que la majorité des abonnés n'utilisent pas leur quota à fond, et qu'Anthropic optimise son infrastructure bien au-delà de ce qu'on peut estimer depuis des benchmarks publics. Partant de là, j'ai l'impression que le prix des abonnements couvre à peu près le coût de leur infrastructure.
L'offre API oblige Anthropic à provisionner des serveurs supplémentaires pour absorber les pics de charge et garantir une bonne qualité de service, et je pense que c'est pour cela que le prix au token est plus élevé via l'API.
Ceci n'est bien sûr que mon estimation personnelle. Si l'un d'entre vous dispose d'une meilleure approche ou de données plus fiables, n'hésitez pas à me la partager : contact@stephane-klein.info.
Équivalence de l'empreinte carbone de l'entrainement de Mistral Large 2
#JaiLu cet article à propos de l'impact environnemental de Mistral Large 2 : « Notre contribution pour la création d'un standard environnemental mondial pour l'IA ».
Bien que cet article ne propose aucun lien vers le rapport complet, le fait que l'étude ait été menée en collaboration avec Carbon 4 me donne confiance. D'autant que Carbon 4 a publié un article dédié sur leur site : « Nouveau jalon dans la transparence environnementale de l'IA générative ».
Dans une note du 14 juillet 2025, j'ai écrit :
Pour Claude Sonnet 3.7 que j'ai fréquemment utilisé, je lis ceci :
- 100 in => 100 out : 0.4g
- 1k in => 1k out : 1g
- 10k in => 10k out : 2g
L'étude de Mistral AI indique un peu plus du double d'émission de CO2 pour l'inférence :
Les impacts marginaux de l'inférence, plus précisément l'utilisation de notre assistant IA Le Chat pour une réponse de 400 tokens:
- 1,14 gCO₂e
- 45 mL d'eau
- 0,16 mg de Sb eq.
1 g pour 1000 tokens versus 1,14g pour 400 tokens.
Concernant l'entrainement de Mistral Large 2, je retiens ceci :
L'empreinte environnementale de l'entraînement de Mistral Large 2 : en janvier 2025, et après 18 mois d'utilisation, Large 2 a généré les impacts suivants :
- 20,4 ktCO₂e,
- 281 000 m3 d'eau consommée, et
- 660 kg Sb eq (unité standard pour l'épuisement des ressources).
Si j'applique le référentiel de ma note du 14 juillet 2025, cette émission de CO2 lors de l'entraînement représente 115 606 trajets aller-retour Paris - Crest-Voland (Savoie) effectués avec ma voiture.
Détail du calcul : 20×1000×1000 / 173 = 115 606.
Voici une estimation grossière pour établir une comparaison.
D'après ce rapport , 8% des Français partent au ski chaque année, soit environ 5 millions de personnes (68 000 000 * 0,08 = 5 440 000).
Selon cet article BFMTV , 90% d'entre elles s'y rendent en voiture.
En supposant 4 personnes par véhicule, cela représente 1,2 million de voitures (5 440 000 * 0,9 / 4 = 1224000).
Si la moitié effectue un trajet de 500 km x 2 (aller-retour), j'obtiens 600 000 trajets.
En reprenant l'estimation d'émission de ma voiture pour cette distance, le calcul donne 600 000 * 172 kg = 103 200 000 kg, soit 130 kt de CO2, ce qui représente plus de 6 fois l'entraînement de Mistral Large 2.
Pour résumer cette Estimation de Fermi : les déplacements des parisiens vers les Alpes pour une saison de ski émettent probablement 6 fois plus de CO2 que l'entraînement de Mistral Large 2.
Dans cette note, mon but n'est pas de justifier l'intérêt de cet entraînement. Je cherchais plutôt à avoir des points de repère et des comparaisons pour mieux évaluer cet impact.
Journal du vendredi 16 mai 2025 à 13:31
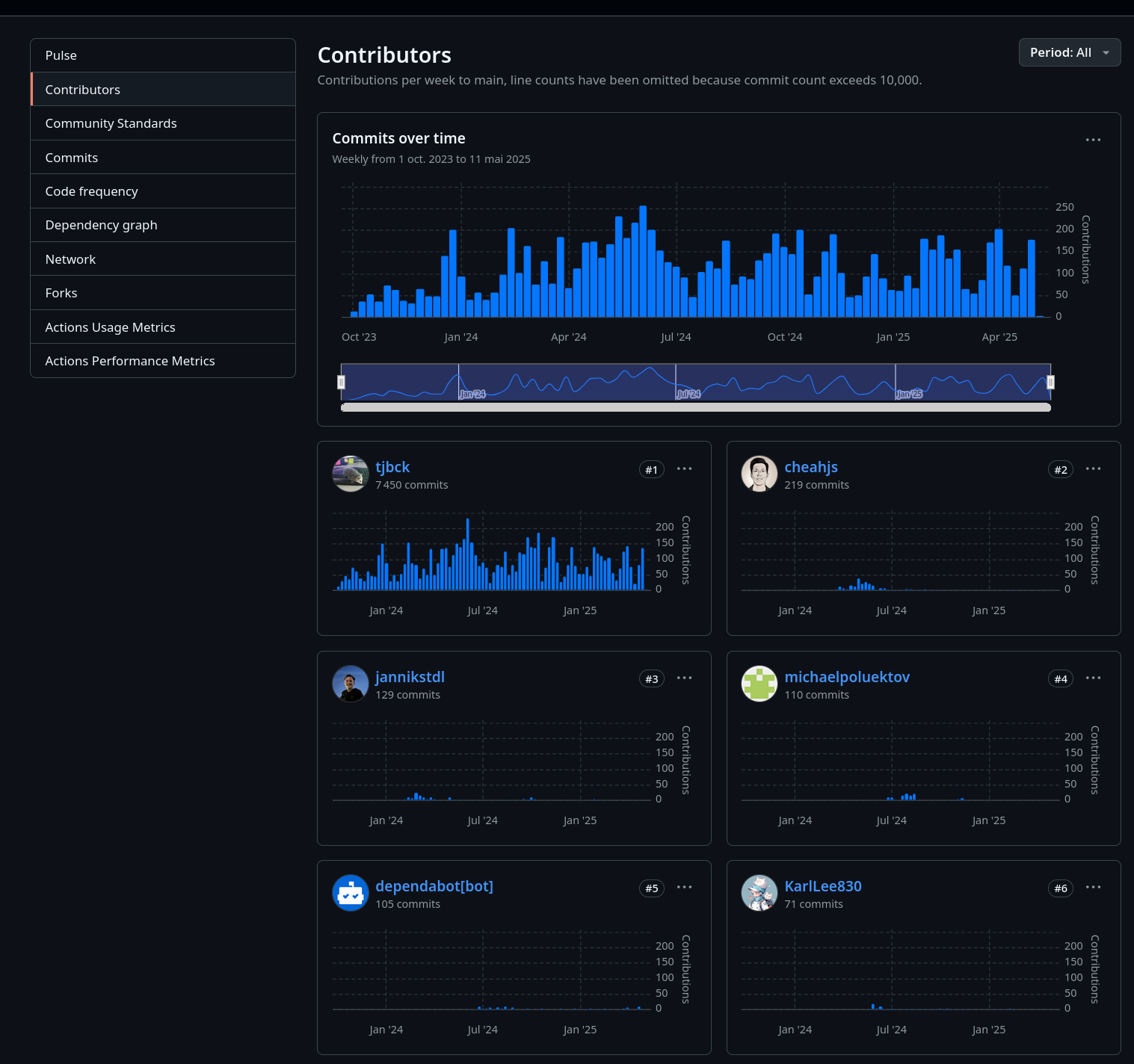
Je me suis posé la question suivante : « Qui contribue au projet Open WebUI ? »
Si je regarde les contributions au projet, je constate que, à la louche, 95% du repository /open-webui/open-webui/ et /pipelines/graphs/ est réalisé par Tim Jaeryang Baek.
Contributions au dépôt /open-webui/open-webui/ :
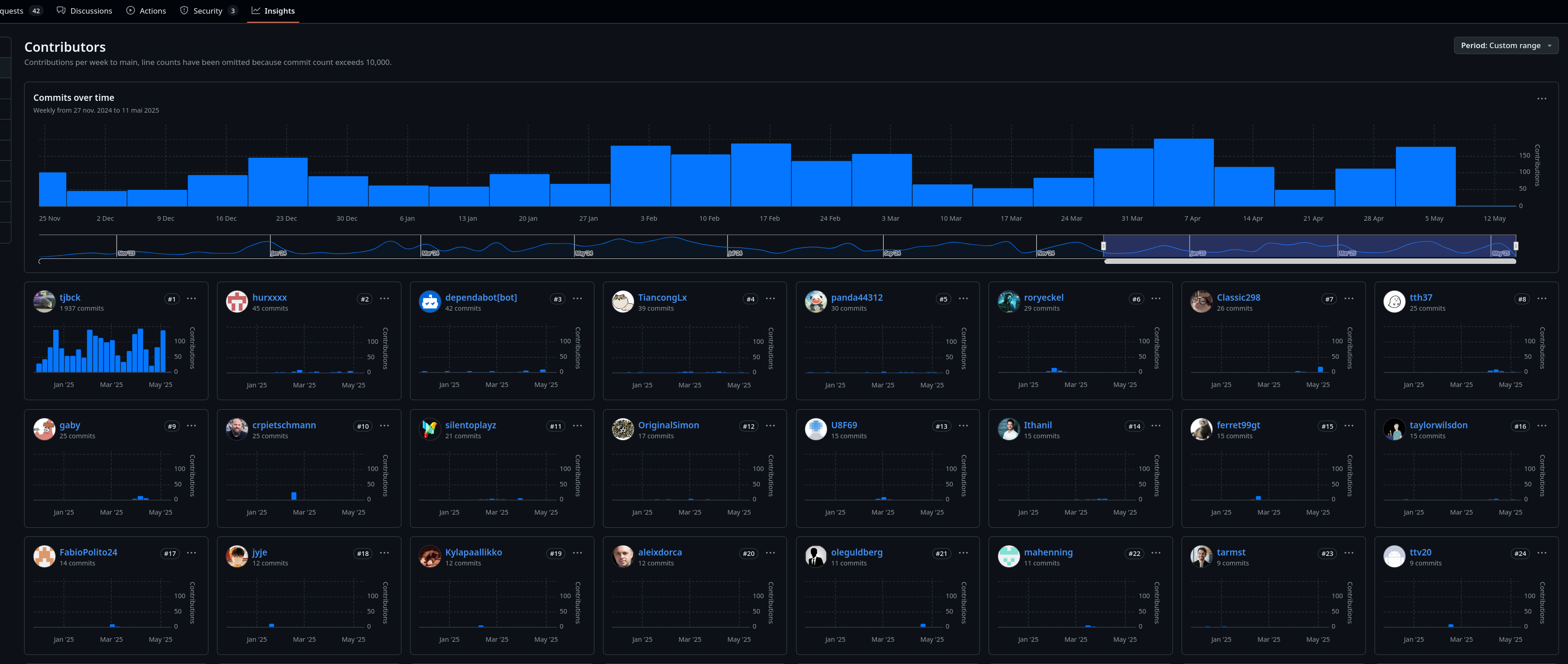
Contributions au dépôt /open-webui/open-webui/ sur les 6 derniers mois :
D'après la section "People" de la page LinkedIn "Open WebUI", James W. semble être dédié et peut-être rémunéré pour travailler sur /open-webui/helm-charts/.
Voici mon estimation de Fermi de calcul du coût de développement d'Open WebUI (seulement ce composant) :
- Estimation du taux journalier de Tim Jaeryang Baek : bien que Tim a commencé depuis peu sa carrière professionnelle, je pense qu'il n'aurait pas de difficulté à trouver des missions entre 500 et 1000 € HT la journée.
- Le dépôt Open WebUI a reçu ses premiers commits le 1ᵉʳ octobre 2023. Cela fait 20 mois de travail.
- Si j'estime, 20 jours de travail par mois sans vacances, j'obtiens 400 jours de travail
- J'obtiens un coût total entre :
- 500 x 400 = 200 000 €
- 1000 x 400 = 400 000 €
Je tiens à préciser que ce montant n'a pas de lien avec une valeur économique d'usage, ni une valeur d'échange.
Comme on a pu le voir au début de cette note, ce projet a été développé par une seule personne, réduisant considérablement les "frais de couplage" (coûts liés à la coordination, communication et synchronisation entre développeurs, management, recrutement…). Si ce même projet avait été réalisé au sein d'une startup, son coût aurait été d'un ordre de grandeur nettement supérieur. Selon mon estimation, il aurait été multiplié par 50, voire davantage.